Methodology
Method Overview
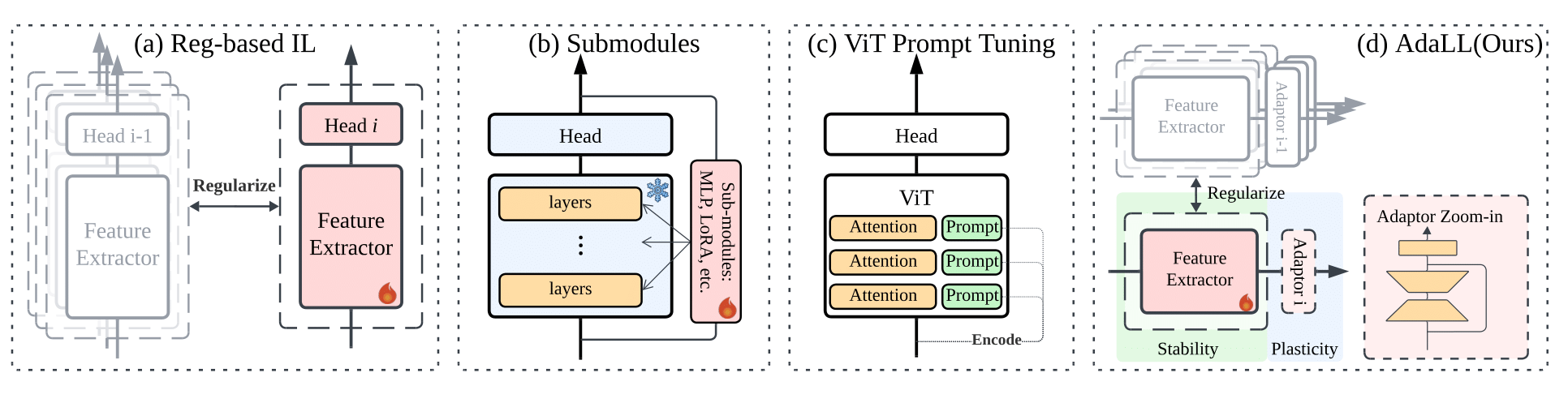
Existing methods contribute to incremental learning in various ways: (a) classic Regularization-based methods, such as LwF and EWC, introduce regularization constraints to preserve knowledge from previous tasks; (b) Submodule-based approaches, for instance InfLoRA and SideTuning, integrate additional components such as MLPs and LoRA into the backbone network; and (c) Prompt tuning methods (DualPrompt, CodaPrompt, etc.) introduces task-specific prefixes to the key and value in attention modules for task-specific performance. We anticipate a novel framework (d) that uses submodules in a way that it can be benefited from regularization and other backbone-specific algorithms to ensure a better response to the stability-plasticity dilemma, i.e. a universal solution.
AdaLL Introduction
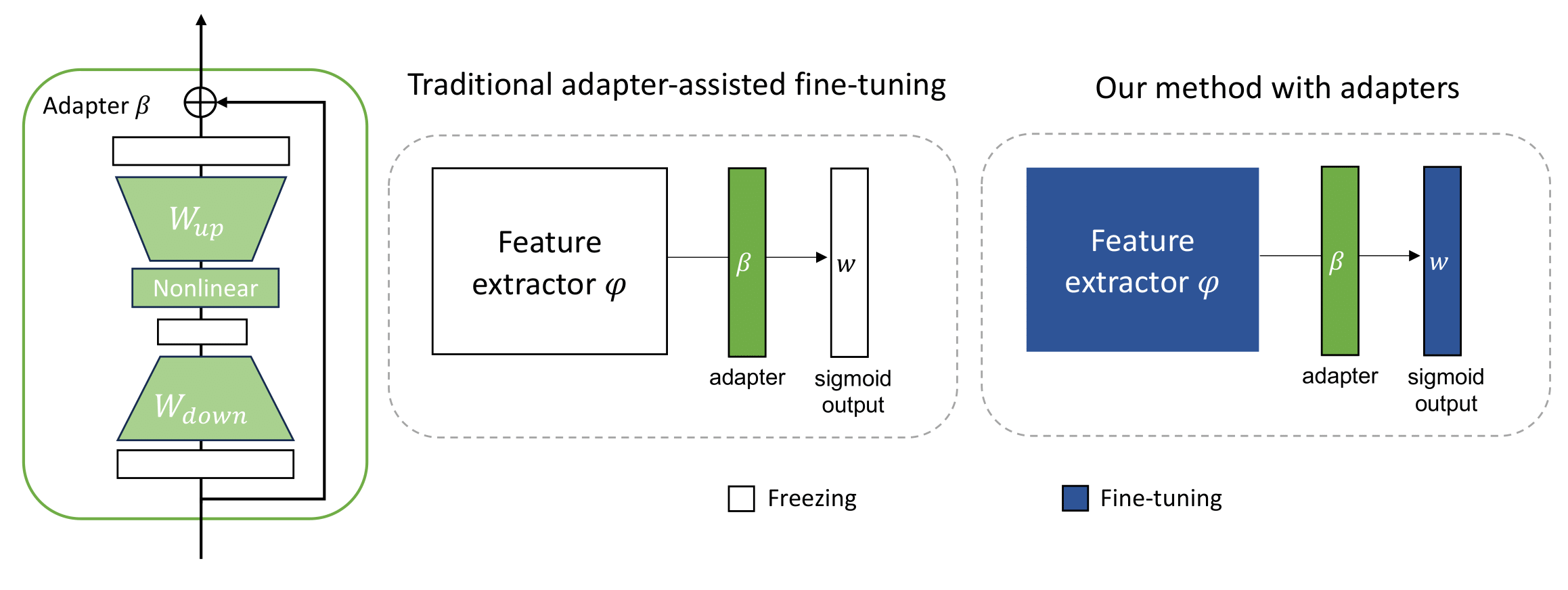
We deploy an adapter that consists of the down-projection, the nonlinear transformation, up-projection, and skip-connection
between the feature exactor and the classifier head. The key difference between traditional use of adapter and ours is that
we co-train adapter with the entire network when learning a new task, in which way we add constraints to ensure that the
backbone keeps the task-invariant information and adapters learn the task-specific information.
We deploy an adapter that consists of the down-projection, the nonlinear transformation, up-projection, and skip-connection between the feature exactor and the classifier head. The key difference between traditional use of adapter and ours is that we co-train adapter with the entire network when learning a new task, in which way we add constraints to ensure that the backbone keeps the task-invariant information and adapters learn the task-specific information.